




Meta 如何大规模训练大型 AI 语言模型?
随着我们越来越专注于用 AI 解决复杂问题,我们面临的一个最大挑战就是训练大语言模型 (LLMs) 所需的庞大计算资源。
传统上,我们训练 AI 模型时,会用相对较少的 GPU 训练大量模型。比如,我们的推荐系统模型(如 feed 和排名模型)会处理大量信息,以提供准确的推荐,从而驱动大多数产品。

随着生成式 AI (Generative AI, GenAI) 的出现,虽然工作量减少了,但每个任务的规模变得巨大。要支持大规模的 GenAI,我们必须重新思考软件、硬件和网络基础设施的整合方式。
大规模模型训练的挑战

随着 GPU 数量在作业中增加,因硬件故障导致中断的可能性也会随之上升。而且,这些 GPU 还需要在同一个高速网络中进行通信才能达到最佳性能。所以,以下四个因素显得尤为重要:
- 硬件可靠性:确保硬件的高可靠性至关重要。我们需要通过严格的测试和质量控制措施,尽量减少硬件故障引发的中断,并利用自动化手段快速检测和解决问题。
- 快速故障恢复:即使硬件故障是不可避免的,当故障发生时,我们需要快速恢复。这就要求尽量减少重新调度的时间,并迅速重新初始化训练。
- 高效保存训练状态: 当训练过程中发生故障时,我们需要能够继续之前的进度。这意味着我们必须定期保存训练状态,并高效地存储和检索训练数据。
- 优化 GPU 之间的连接: 大规模模型训练需要在 GPU 之间同步传输大量数据。如果部分 GPU 之间的数据交换速度比较慢,会导致整体任务的速度放缓。解决这个问题需要建立一个强大且高速的网络基础设施,并且采用高效的数据传输协议和算法。
基础设施栈的创新
为了满足大型生成式 AI (GenAI) 对规模的需求,完善基础设施栈的每一层变得至关重要。这涉及到多个领域的发展和创新。
训练软件
我们使研究人员能够使用 PyTorch 和其他新的开源开发技术,从而极大地加速了从研究到生产的转化过程。这包括开发新算法和技术进行高效的大规模训练,并将新的软件工具和框架集成到我们的基础设施中。
调度
高效的调度有助于确保我们资源的最佳利用。这需要采用复杂的算法,根据不同任务的需求分配资源,并通过动态调度应对不断变化的工作负载。
硬件
要应对大规模模型训练的计算需求,我们需要高性能的硬件。不仅是规模和大小,许多硬件配置和属性也需要为生成式 AI (GenAI) 做出最佳优化。由于硬件开发通常需要较长时间,我们不得不改用现有硬件,因此我们从多个方面进行了探索,包括功耗、HBM (高带宽存储) 的容量和速度,以及输入输出 (I/O) 。
我们还对 Grand Teton 平台进行了调整,该平台使用 NVIDIA H100 GPU。我们将 GPU 的热设计功耗 (TDP) 提高到 700W,并改用 HBM3 存储。由于没有时间更改冷却系统,我们保留了空气冷却方式。为此,我们的机械和热设计也进行了相应修改,以便能够支持大规模部署,这也触发了一个新的验证周期来确保系统的可靠性。所有这些与硬件相关的更改都非常具有挑战性,因为我们必须在受限的资源条件下找到适用的解决方案,并且可调整的范围非常小,还要满足紧迫的时间要求。
数据中心部署
一旦我们选择了 GPU 和系统,就需要考虑如何将它们放置在数据中心,以便优化资源使用(如电力、冷却和网络等)。需要重新审视为其他类型工作负载所做的权衡。数据中心的电力和冷却基础设施无法快速(或轻易)改变,我们必须找到一种最佳布局,使数据大厅内的计算能力最大化。为此,我们需要将支持服务(如读器)移出数据大厅,并尽可能多地安装 GPU 机架,以在一个大型网络集群中最大化计算密度和网络能力。
可靠性
为了减少硬件故障带来的停机时间,我们需要制定检测与修复计划。随着集群规模的扩大,故障数量也会增加,因此对于跨集群的任务,我们必须保持足够的备用容量,确保任务能够尽快重新启动。此外,通过监控故障情况,我们可以有时采取预防措施,进一步减少停机时间。
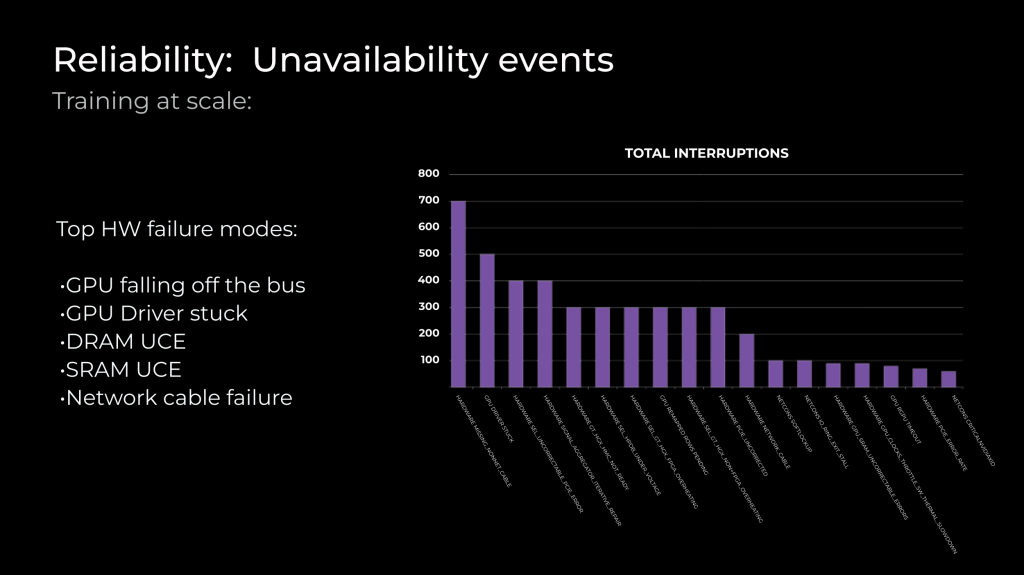
我们观察到的常见故障模式包括:
- GPU 脱离: 在这种情况下,主机无法通过 PCIe 总线检测到 GPU。尽管这种故障有多种可能的原因,但在服务器的初期使用阶段更为常见,随着时间推移会逐渐减少。
- DRAM 和 SRAM UCE: 内存中常见不可纠正错误(UCE)。我们会监控并识别频繁出现的错误,将其与阈值比较,并在错误率超过厂商设定的阈值时启动 RMA 流程。
- HW 网络电缆: 在无法访问的服务器中,这些故障通常发生在服务器使用初期。
网络
大规模模型训练需要在 GPU 之间快速传输海量数据,因此需要强大且高速的网络基础设施,以及高效的数据传输协议和算法。在业界,有两种主要选择能够满足这些需要:RoCE 和 InfiniBand 结构。但这两种选择各有优劣。一方面,Meta 在过去四年里已经建设了 RoCE 集群,但这些集群最大只能支持 4K 个 GPU。我们需要更大规模的 RoCE 集群。另一方面,Meta 也已经建设了使用 InfiniBand 的研究集群,规模可以达到 16K 个 GPU 16K GPUs。不过,这些集群并未紧密整合到 Meta 的生产环境中,也没有针对最新一代的 GPU 和网络进行构建。这使得选择使用哪种结构变得相当困难。于是我们决定同时构建两种集群:两个 24k 集群,一个使用 RoCE,另一个使用 InfiniBand。通过实际操作,我们希望能从中学习经验,这些经验将为未来的 GenAI 网络架构提供方向。我们将 RoCE 集群优化以缩短构建时间,而将 InfiniBand 集群优化以实现全双工带宽。我们在训练 Llama 3 时同时使用了 InfiniBand 和 RoCE 集群,其中 RoCE 集群负责训练最大的模型。尽管这两个集群的底层网络技术有所不同,但我们还是成功地调优它们,使它们在大型 GenAI 工作负载下表现出相同的性能。

为提升 GenAI 模型在这两个集群上的网络通信性能,我们对整体架构的三个方面进行了优化:1. 我们将由于不同模型、数据和流水线并行性产生的通信模式分配给网络拓扑的不同层次,以充分利用网络的能力。 2. 我们引入了考虑网络拓扑特性的集体通信模式,减少其对延迟的敏感度。我们通过使用自定义算法,例如递归双倍或递归减半,来替换传统的环形算法,实现这一点。 3. 生成式 AI 作业会产生额外的大流量,难以将流量均匀分配到所有可能的网络路径。这需要我们进一步投资网络负载均衡和路由,以实现对网络资源的最佳分配。我们在 Networking @Scale 2023 会议中,详细介绍了我们的 RoCE 负载均衡技术。
存储
为了存储模型训练所需的海量数据,我们需要高效的数据存储解决方案。这不仅需要投资大容量和高速存储技术,还需针对特定工作负载开发新的数据存储方法。